URLの正規化とは?
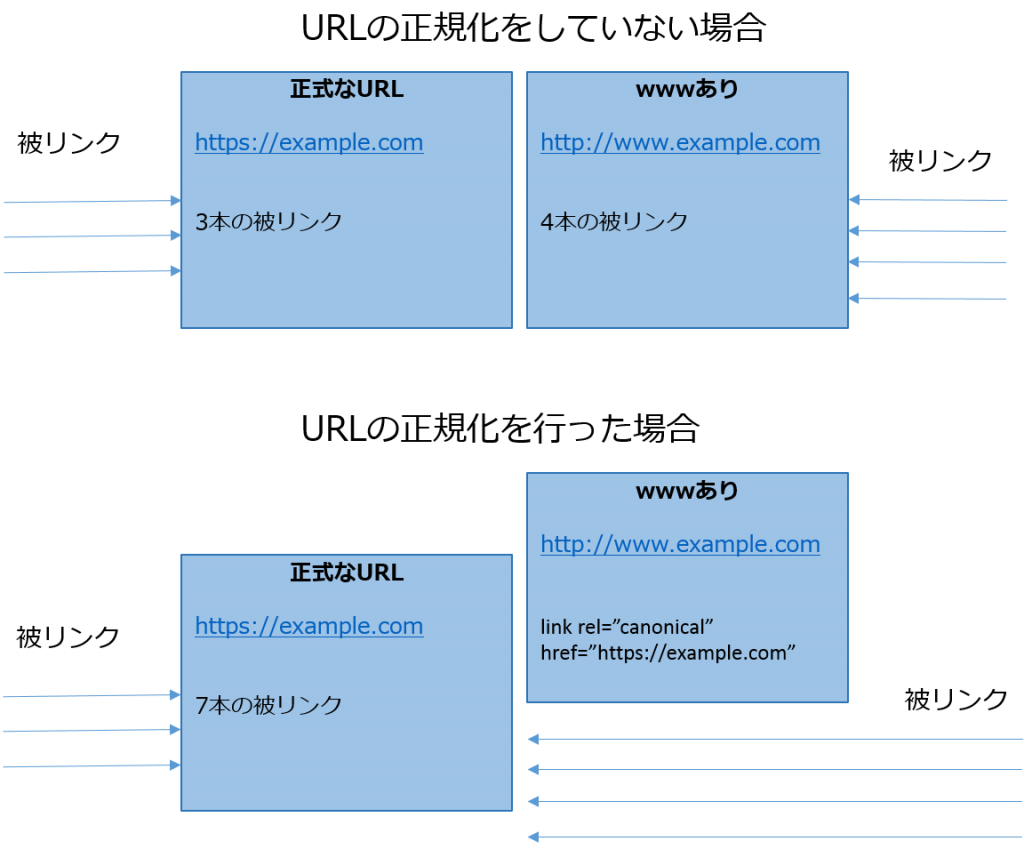
URLの正規化とは、重複する、または類似のコンテンツで分散している検索エンジンの被リンク評価を、正規のURLに統合してもらう事を意味します。
Googleは特に何もしなくても重複するURLを一つのURLに集約しようとします。
例えば「url.htm?utm=greencheeseandham」と「url.htm」の二つのURLで共通するコンテンツが表示されていた場合には、短い方のURL 「url.htm」 で正規化されます。
ただし、必ずしもウェブサイト運営者の思う通りに評価が統合されるとは限りません。
評価やインデックスをコントロールする為には、canonical属性で正規URLを指定しておきましょう。
canonical属性とは?
canonical属性とは、この正規URLを指定する際に使用する記述方法です。
canonicalはカノニカルと発音し、英語では「正統」、「標準」といった意味になります。
Googleの処理におけるクラスタリングと正規化の違い
GoogleのAllan Scott氏によれば、クラスタリングと正規化は、重複コンテンツの処理における2つの異なるステップです:
- クラスタリング:Googleが同一または非常に類似していると判断したページをグループ化するプロセス。この段階では、重複する可能性のあるページが同じクラスタにまとめられます。
- 正規化(canonicalization):クラスタ内のページから、検索結果に表示する最も適切なURLを選択するプロセス。これは、ユーザーにとって最も関連性が高く、信頼性のあるページを提供するために行われます。
John Mueller氏はこの関係を「クラスタリングは同じと判断したページをまとめること。正規化は、その中から最適な1ページを選ぶこと」と要約しています。
canonical属性で正規URLの指定が必要な理由
以下のようなケースでは表示される内容は同じであっても、URLのパターンは複数存在します。
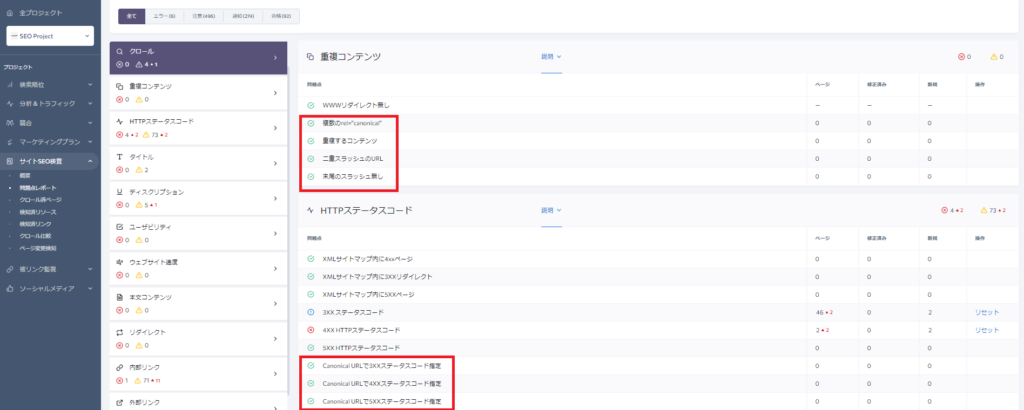
正規化の必要性がある様々なURLパターン
| 有りのバーション | 無しのバーション | |
|---|---|---|
| www | http://www.allegro-inc.com | http://allegro-inc.com |
| index.html | https://www.allegro-inc.com/index.html | https://www.allegro-inc.com |
| https | https://www.allegro-inc.com | http://www.allegro-inc.com |
| パラーメータ | https://www.allegro-inc.com/?ref=blog | https://www.allegro-inc.com |
Googleは、このような複数のパターンのURLを別のページとして認識してそれぞれ評価してしまいます。または自動的に重複するページとして評価を統合する事もありますが、そうでない場合もあり得ます。
評価の分散を防ぐためには、自身のウェブサイトのリンクの張り方を統一するという方法が有効ですが、外部サイトからのリンクに関してはコントロールできません。このような場合を想定してcanonical属性を使用して正規URLを指定しておくと評価を統合する事ができます。

これらの他にもABテストを実施する際にもcanonical属性を使用します。詳しくは「Webサイトテスト時にGoogle検索への影響を抑える方法」をご覧ください。
正規URLの指定方法
canonical属性を使用した正規URLの指定方法は以下の2パターンあります。
- HTMLのheadタグ内に記述する方法
- HTTPヘッダーで指定する方法
- XMLサイトマップで正規URLをまとめる(1,2の方法よりは強制力が弱い)
1の方法は最も一般的な方法で、2の方法は例えばPDFファイルなど、1の方法で指定できない場合に代わりにHTTPヘッダーでcanonical属性を指定する事ができます。3の方法も検索エンジンが正規URLを判断する際のシグナルになるようです。
It’s normal to have some duplicate content on your site, but you want to give search engines as many hints as you can about which version should be canonical (I.e. shown in search results). Sitemaps is one of those hints. Not as strong as rel-canonical and definitely not even near redirects, but it can be useful still.
Gary Illyesのコメント
HTMLのheadタグ内に記述する方法
以下のようにheadタグ内に記述する事で、wwwあり、なし、パラメータ付のurlなどを一つのURLに正規化し、検索エンジンのインデックスを統一する事ができます。
<head>
・
<link rel=”canonical” href=”https://example.com/product.php”>
・
</head>
HTTPヘッダーで指定する方法
例えば、コンテンツが同じで、以下の2つのURLが存在したとします。white-paper.pdfのHTML版がwhite-paper.htmlです
- http://www.example.com/white-paper.html
- http://www.example.com/white-paper.pdf
canonical属性を指定しなければ、Googleはどちらも別々のURLとして判断する為、リンク評価が分散してしまいます。
しかし、一方はPDFファイルの為、HTMLではない為、headタグ内にcanonical属性は記述できません。
このような場合はGoogleが「http://www.example.com/white-paper.pdf」にアクセスした際にHTTPヘッダーを使ってHTML版のURL「http://www.example.com/white-paper.html」が正規なURLである事を示して、評価を統合する事ができます。
設定後に確認するにはChromeであれば検証機能の「Network」タブをクリックして、該当のファイルを選択します。
次のように表示されているか確認しましょう。
GET /white-paper.pdf HTTP/1.1
Host: www.example.com
(…以下、他の HTTP リクエスト ヘッダー…)
HTTP/1.1 200 OK
Content-Type: application/pdf
Link: <http://www.example.com/white-paper.html>; rel=”canonical”
Content-Length: 785710
(…以下、他の HTTP レスポンス ヘッダー…)
正規化に関するよくある質問
正規化の注意点
次の例のように、hreflang, lang, media type とrel=”canonical”アノテーションはセットで使用できません。
- <link rel=”canonical” hreflang=”en” href=”https://example.com/dresses/green-dresses” />
- <link rel=”canonical” lang=”ja” href=”https://example.com/dresses/green-dresses” />
- <link rel=”canonical” href=”https://example.com/dresses/green-dresses” media=”screen and (max-width:480px)” />
正規化処理が行われるまでの時間
実際は、canonical属性によるURL正規化を行ったからといってすぐにGoogleの方で認識されるという事はないようです。リクエストとして受け取り、指定ミスの可能性が無いか確かめた上で最終的に処理されるようです。
その為、URLが正規化されるまでにはある程度時間がかかるようです。
John Mueller氏のコメントでは、rel=canonicalを指定したからといって、記述通りに処理されない事もあるようです。正規化を決定する為に、Googleは複数の要素を見ている為、このような事は起こり得るようです。
良くあるミスとしては、ウェブサイト内の全てのページでトップページを正規URLに指定しているケースがあります。このような場合はGoogleはミスとして認識して、記述自体を無視するようです。
URL内の/(スラッシュ)の有無による認識の違い
GoogleのJohn Muller氏のコメントでは、/(スラッシュ)の有無や位置によってGoogleに認識の違いが生じるようです。
- http://www.example.com/
- http://www.example.com
- https://www.example.com/
- https://www.example.com
- https://example.com/
- https://example.com/fish
- https://example.com/fish/
①と②、③と④のようなホスト名の後のスラッシュの有無で問題は生じないようです。つまり①と②は同じ、③と④は同じと認識されます。
一方でホスト名とプロトコルでは、異なるURLとして扱われます。つまり①と③は異なり、③と⑤も異なる為、別のURLとして認識されます。
パス/ファイル上のスラッシュの扱いも同様に別のURLとして認識されます。つまり⑥と⑦は別のURLとして認識されます。
ページネーションで2ページ目以降から1ページ目に正規化してはいけない
ページネーションで使用するページに重複コンテンツはないはずです。このような使い方をすると、ページネーションの2番目のページは表示されても、3ページ目以降は検索結果から除外される場合があり、コンテンツの評価を失うことになります。
検索結果に1ページ目を表示させたい場合はページネーションで使用するページを一つにまとめたコンポーネントページを作り、そこに向けてrel=canonicalを指定する方法があります。
rel=canonicalで指定するURLは絶対パスを記述
URLの指定は、絶対パスと相対パスというものがあります。絶対パスの場合は、「https://」から記述します。相対パスではwwwの有無、http/httpsの判別、サブドメインかどうかの判断などが曖昧なため、絶対パスを指定する必要があるようです。
PSA from my inbox: don’t use relative paths in your rel-canonical.
Just don’t. Spell it out:
<link rel=”canonical” href=”https://example.com/cats” />
The few bytes you could save wouldn’t break the bank anyway.
Gary Illyes氏のコメント
このほか、記述上で「href=”www.allegro-inc.com”」と指定してしまうミスは一般的に多いかもしれません。検索エンジンは「http://www.allegro-inc.com/www.allegro-inc.com」として認識してしまいます。
正規化に誤りがあった場合
2024年12月6日、Search Engine RoundtableのBarry Schwartz氏は、Googleが誤ったまたは壊れたrel="canonical"タグに対処する方法について報告しました。Googleの検索チームで重複コンテンツの処理を担当するAllan Scott氏は、公式ポッドキャスト「Search Off The Record」で、Googleが不正確なcanonicalタグに対して検証を行い、必要に応じて無効化する仕組みを持っていることを明らかにしました。
Googleの対応とその限界
Scott氏によると、Googleは以下のようなケースでcanonicalタグを無効化することがあります:
- スクリプトのエラーにより、
rel="canonical"がhostname/$variableのような無効なURLを指している。 rel="canonical"が空欄で、結果としてルートディレクトリ(/)を指してしまう。
しかし、これらの検証機能は完全ではなく、すべての誤りを検出できるわけではありません。Scott氏は、より高度な検証機能の開発が進行中であるものの、現時点では既存の仕組みに依存していると述べています。
その他一般的な注意点
- 重複しているページコンテンツと正規化したURLのコンテンツの大部分が同じである事を確認する。
扱うトピックは類似したものであっても、全く同じ単語や文章でなかった場合にはcanonicalの指定は無視されるかもしれません。 - rel=canonicalのターゲットが存在するか確認する(404エラー、ソフト404がない)
ソフト404はページ上では404エラーと表示されていても、サーバーからは404エラーをブラウザに返していない状態を言います。 - rel=canonicalのターゲットがrobotsメタタグでnoindexとなっていないか確認する。
- rel=canonicalで指定したURLは検索結果に表示させたいURLであるか確認する。誤って正規ではない重複するURLを指定していない事を確認しましょう。
- rel=canonicalのリンクがhttpヘッダーまたはページの<head>タグ内に含まれている事を確認する。
- rel=canonicalがページ内に複数存在していないか確認する。
複数あると検索エンジンに無視されます。 - 正規化の為にrobots.txtを使用しない。robots.txtで重複コンテンツをブロックすると各ページの評価を失い、結果的に評価が薄まってしまいます。
- 正規化に指定するURLはピュニコード化されていても、されていなくてもどちらもGoogleは認識できる。
- URL正規化の問題解決のためにURL削除ツールを使用しない。
- Google は通常 URL フラグメントをサポートしていないため、URL フラグメントは使用しない。
canonicalのエラーを一括で抽出する方法
SE RankingのサイトSEO検査ツールでは、canonicalの指定ミスも含め、ウェブサイトの全てのページのSEOに関する問題点を抽出してくれます。以下の手順で操作をお試しください。
クレジットカード登録不要で、2週間無料のトライアルアカウントを作成できます。以下のページから登録をお試しください。
以下の導入手順を参考に、プロジェクトを作成します。
SE Rankingにログインし、左メニューの「サイトSEO検査」にアクセスし、検査を実行します。
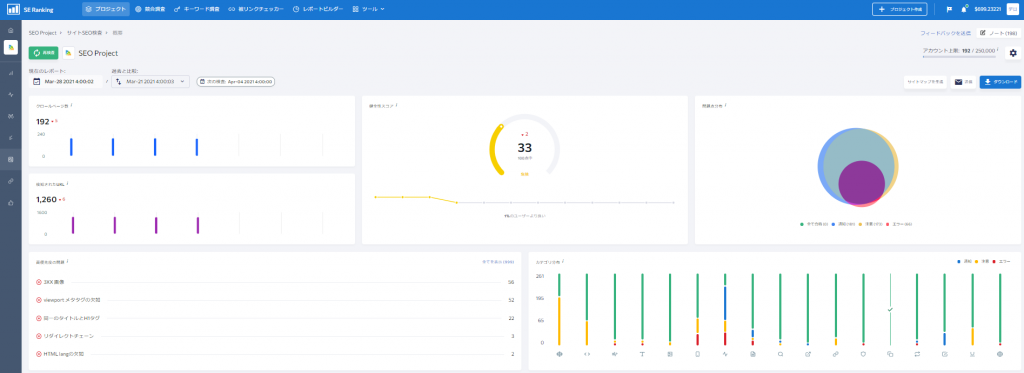
検査完了後に、左メニューの「サイトSEO検査」内のサブセクションの「問題点レポート」にアクセスします。
重複コンテンツやcanonicalの指定ミスに関するエラーが一括で抽出されます。エラーが表示されている場合は、表の「ページ」列の数字部分をクリックして、該当ページを確認しましょう。